Java 常用类库
※ 斜体的为线程安全的数据结构
线性结构
- List: ArrayList、CopyOnWriteArrayList、Vector
- Queue: LinkedList、PriorityQueue、BlockingQueue、ConcurrentLinkedQueue
- Stack: extends from Vector
非线性结构
- Set: HashSet、LinkedHashSet、TreeSet、CopyOnWriteArraySet、ConcurrentSkipListSet
- Map: HashMap、TreeMap、WeakHashMap、IdentityHashMap、LinkedHashMap、Hashtable、ConcurrentHashMap、ConcurrentSkipListMap
集合包装类
- 不可变更集合类:Collections.unmodifiableCollection()
- 同步集合类:Collections.synchronizedCollection()
- 可检查集合类:Collections.checkedCollection()
Java 反射机制
历史由来
反射这一概念,主要指应用程序访问、检测、修改自身状态与行为的能力。
反射机制
Java 的反射(reflection)机制是指在程序的运行状态中,动态获取程序信息以及动态调用对象的功能。 其中主要的功能有:
- 在运行时判断一个对象所属的类
- 在运行时构造一个类的对象
- 在运行时判断一个类所具有的成员变量和方法
- 在运行时调用一个对象的方法
优势
- 提高灵活性和扩展性,降低耦合性,提高自适应能力
- 允许程序创建和控制任何类的对象,无需硬编码目标类
反射获取类名
public static void main(String[] args) throws ClassNotFoundException {
// 方法1: Class.forName("类名字符串")
// 类名字符串必须是全称, 包名 + 类名
Class<?> cls1 = Class.forName("java.lang.String");
// 方法2: 类名.class
Class<String> cls2 = String.class;
// 方法3: 实例对象.getClass()
String s = new String();
Class<? extends String> cls3 = s.getClass();
// 方法4: "类名字符串".getClass()
String str = "java.lang.String";
Class<? extends String> cls4 = str.getClass();
System.out.println(cls1); // class java.lang.String
System.out.println(cls2); // class java.lang.String
System.out.println(cls3); // class java.lang.String
System.out.println(cls4); // class java.lang.String
}
反射获取类的构造函数
// 获取 参数是parameterTypes 的public构造函数
Constructor<?> constructor = cls1.getConstructor(String.class);
System.out.println(constructor.toString()); // public java.lang.String(java.lang.String)
// 获取全部public构造函数
Constructor<?>[] constructors = cls1.getConstructors();
for (Constructor<?> c : constructors) {
System.out.println(c.toString()); // public java.lang.String(byte[]) ...
}
// 获取 参数是parameterTypes 的类自身声明的构造函数 (public, protected, private)
Constructor<?> declaredConstructor = cls1.getDeclaredConstructor(char[].class);
System.out.println(declaredConstructor.toString()); // public java.lang.String(char[])
// 获取全部 类自身声明的构造函数 (public, protected, private)
Constructor<?>[] declaredConstructors = cls1.getDeclaredConstructors();
for (Constructor<?> dc : declaredConstructors) {
System.out.println(dc.toString()); // public java.lang.String(byte[]) ...
}
// 若这个类是 其他类的构造函数中的内部类
// 若不是 则会返回 null
Optional<Constructor<?>> enclosingConstructor = Optional.ofNullable(cls1.getEnclosingConstructor());
System.out.println(enclosingConstructor.orElse(null)); // null
反射获得类的成员方法
Method method1 = cls1.getMethod("equals", Object.class);
System.out.println(method1.toString()); // public boolean java.lang.String.equals(java.lang.Object)
Method[] methods = cls1.getMethods();
for (Method method : methods) {
System.out.println(method.toString()); // public boolean java.lang.String.equals(java.lang.Object) ...
}
Method method2 = cls1.getDeclaredMethod("length");
System.out.println(method2.toString()); // public int java.lang.String.length()
Method[] declaredMethods = cls1.getDeclaredMethods();
Optional<Method> enclosingMethod = Optional.ofNullable(cls1.getEnclosingMethod());
反射获得类的字段
Field field1 = cls1.getField("CASE_INSENSITIVE_ORDER");
System.out.println(field1.toString()); // public static final java.util.Comparator java.lang.String.CASE_INSENSITIVE_ORDER
Field[] fields = cls1.getFields();
for (Field field : fields) {
System.out.println(field.toString()); // public static final java.util.Comparator java.lang.String.CASE_INSENSITIVE_ORDER
}
Field field2 = cls1.getDeclaredField("CASE_INSENSITIVE_ORDER");
Field[] declaredFields = cls1.getDeclaredFields();
反射获得类的注解
Class<?> cls = Class.forName("java.util.function.BiConsumer");
Annotation annotation1 = cls.getAnnotation(FunctionalInterface.class);
System.out.println(annotation1.toString()); // @java.lang.FunctionalInterface()
Annotation[] annotations = cls.getAnnotations();
for (Annotation annotation : annotations) {
System.out.println(annotation.toString()); // @java.lang.FunctionalInterface()
}
Annotation[] declaredAnnotations = cls.getDeclaredAnnotations();
// 该类是不是本地类 (定义在方法内部的类)
boolean isLocalClass = cls.isLocalClass();
System.out.println(isLocalClass); // false
// 该类是不是基本类型
boolean isPrimitive = cls.isPrimitive();
System.out.println(isPrimitive); // false
缺点
- 对性能有影响。使用反射是一种解释操作,需要动态访问JVM以满足要求。
- 一般来说,此类访问操作慢于直接执行java代码。若无必要的情况下,不建议基于反射特性进行编码。
Class<?> cls1 = Class.forName("java.lang.String");
System.out.println(cls1); // class java.lang.String
Method[] methods = cls1.getDeclaredMethods();
for (Method method : methods) {
System.out.println(method.toString());
}
// byte[] java.lang.String.value()
// public boolean java.lang.String.equals(java.lang.Object)
// ...
Java 线程同步
数据同步
volatile关键字Atomic类- Double-Check 法则
隐式锁
synchronized关键字
显式锁
- lock 锁使用方式
- lock 锁的持有与释放
volatile关键字
public class NoVisibility {
//private static boolean ready; // 非volatile变量可能导致 Reader线程永远无法退出
private static volatile boolean ready; // volatile变量使变量在线程间进行可见性保证
private static class ReaderThread extends Thread {
@Override
public void run() {
while (!ready) {
// ...
}
}
}
public static void main(String[] args) {
new ReaderThread().start();
ready = true;
}
}
volatile 的作用就是使变量在线程间进行可见性保证;
根据 JVM 内存模型,volatile 修饰的变量会保证各个线程读取其时都是在最新的写操作完成之后。
Atomic类
public class CountDemo {
public static volatile int count;
private static class CountThread extends Thread {
@Override
public void run() {
count++;
System.out.println(count);
}
}
public static void main(String[] args) {
Thread t1 = new CountThread();
Thread t2 = new CountThread();
t1.start();
t2.start();
}
}
但是 volatile 只能保证内存可见性,并不能保证操作原子性,要使用 AtomicInteger 来实现自增操作。
import java.util.concurrent.atomic.AtomicInteger;
public class CountDemo {
public static AtomicInteger count = new AtomicInteger(0);
private static class CountThread extends Thread {
@Override
public void run() {
count.getAndIncrement();
System.out.println(count);
}
}
public static void main(String[] args) {
Thread t1 = new CountThread();
Thread t2 = new CountThread();
t1.start();
t2.start();
}
}
Atomic 的作用是保障单独自增/自减等操作的原子性(但注意:多个原子性操作叠加之后并不是原子的)
Double-Check 法则
经典的 DCL 懒汉式单例
public class Singleton {
private static volatile Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
private Singleton() {}
}
解析
- Double-Check 的目的式延迟单例初始化的一种方法
- 使用
volatile的主要目的是防止指令重排序 - 第一层 if 判断是为了减少多次
synchronized,减少每次都同步,提升性能 - 第二层 if 判断是为了防止锁释放后创建出多个实例
同步方法和同步块(隐式锁)
public class SomeObject {
private final Object lock = new Object(); // (!)
public void changeValue() {
synchronized (lock) {
// locks on the private Object
// ...
}
}
}
public class SomeObject {
public static final Object lock = new Object(); // 使用 public 的静态锁对象进行同步操作
public void changeValue() {
synchronized (lock) {
// locks on the private Object
// ...
}
}
}
// Untrusted code
class OtherClass {
public static void main(String[] args) throws InterruptedException {
synchronized (SomeObject.lock) {
while (true) {
// Indefinitely delay SomeObject
Thread.sleep(Integer.MAX_VALUE);
}
}
}
}
外部不可信代码可以直接无限期持有 SomeObject.lock 这把锁,阻塞 changeValue() 的执行…
public class SomeObject {
// Locks on the object's monitor
public synchronized void changeValue() {
// ...
}
}
class CacheUtil {
public static void setSomeObject(SomeObject obj) {
// ...
}
public static SomeObject getSomeObject() {
return new SomeObject();
}
}
// Untrusted code
class OtherClass {
public static void main(String[] args) throws InterruptedException {
SomeObject someObject = CacheUtil.getSomeObject();
// 不可信代码企图获取对象监控器上的锁
synchronized (someObject) {
while (true) {
// Indefinitely delay SomeObject
Thread.sleep(Integer.MAX_VALUE);
}
}
}
}
一旦成功,将引入一个无限期的时延来阻止声明为同步的方法 changeValue() 来获取同一个锁…
public final class CountBoxes implements Runnable {
private static volatile int counter;
// ...
private final Object lock = new Object();
@Override
public void run() {
synchronized (lock) { // 使用一个实例锁 来同步 共享静态数据
counter++;
System.out.println(counter);
// ...
}
}
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
new Thread(new CountBoxes()).start();
}
}
}
实例锁在两个或多个实例的情况下是无效的,导致并发时的线程同步会失效…(对静态变量的同步要使用静态锁)
public final class CountBoxes implements Runnable {
private static volatile int counter;
// ...
@Override
public synchronized void run() { // 使用方法同步 来同步共享静态数据
counter++;
System.out.println(counter);
// ...
}
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
new Thread(new CountBoxes()).start();
}
}
}
方法同步使用的是每个对象的内置锁,而不是类本身的内置锁…(对静态变量的同步要使用静态锁)
// 使用可被重用的对象进行同步
// (X)
private final Boolean lock = Boolean.FALSE;
// (X)
private int count = 0;
private final Integer lock = count;
// (X)
private final String lock = new String("LOCK").intern();
private final String lock = "LOCK";
// (O) new出来的Integer对象 具有唯一索引
private int count = 0;
private final Integer lock = new Integer(count);
// (O) new出来的(没进入常量池的)String对象 具有唯一索引
private final String lock = new String("LOCK");
基础数据类型作为锁对象使用时,这些锁对象可被其他线程重用,进而会导致死锁等不正确的线程同步行为…
高层并发对象(显式锁)
private final Lock lock = new ReentrantLock();
public void doSomething() {
boolean isLocked = lock.tryLock();
if (isLocked) {
try {
// ...
}
finally {
lock.unlock();
}
}
}
private final Lock lock = new ReentrantLock();
public void doSomething() {
lock.lock();
try {
// ...
}
finally {
lock.unlock();
}
}
Java 线程规范与管理
线程规范
- 创建新线程要指定名称
- 不要依赖线程调度器、线程优先级、
yield()方法 - 采用 Java 1.5 提供的新并发工具代替
wait()和notify()- Executor Framework
- Concurrent Collection(并发集合)
- Synchronizer(同步器)
线程管理
- 禁用
Thread.run() - 禁用
Thread.stop() - 线程中断由业务代码来协作完成,慎用
Thread.interrupt()方法 - 避免不加控制地创建新进程,而应该使用线程池来管控资源
正确的线程启动与结束流程
public final class MyTask implements Runnable {
private volatile boolean isFinished = false;
@Override
public void run() {
while (!isFinished) {
// ...
}
}
public void finish() {
isFinished = true;
}
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
Thread thread = new Thread(task, "task001");
thread.start();
Thread.sleep(5000);
task.finish();
}
}
垃圾回收
垃圾回收介绍
- 什么是垃圾回收(Garbage Collection)?
- 把不用的内存回收掉
- Java 采用自动内存管理技术,内存分配后由虚拟机自动管理
- 优缺点:
- 优点:程序员不需要自己释放内存,只管 new 对象即可
- 缺点:GC 本身有开销,会挤占业务执行资源
- 什么是垃圾:
- 不会被访问到的对象是垃圾
垃圾识别算法
- 引用计数法
原理:
- 记录每个对象被引用的数量,当被引用的数量为 0 时,则标记为垃圾
- 缺点:无法处理循环引用的问题
示例:
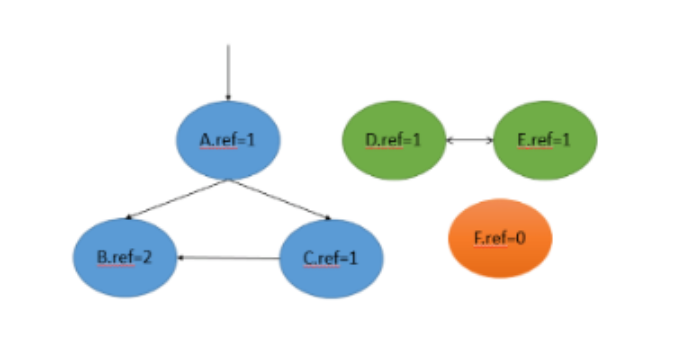
- 对象 A、B、C 不是垃圾
- 对象 F 是垃圾,引用计数为 0,被回收
- 对象 D、E 是垃圾,但引用计数不为 0,出出现内存泄漏
- 可达性分析法
原理:
- 从 GC Roots 开始遍历对象,没有被遍历到的对象为垃圾
GC Roots:
- 方法栈使用到的参数、局部变量、临时变量等
- 方法区中类静态属性引用的变量
- 方法区中常量引用的对象
- 本地方法栈中 JNI 引用的对象
示例:
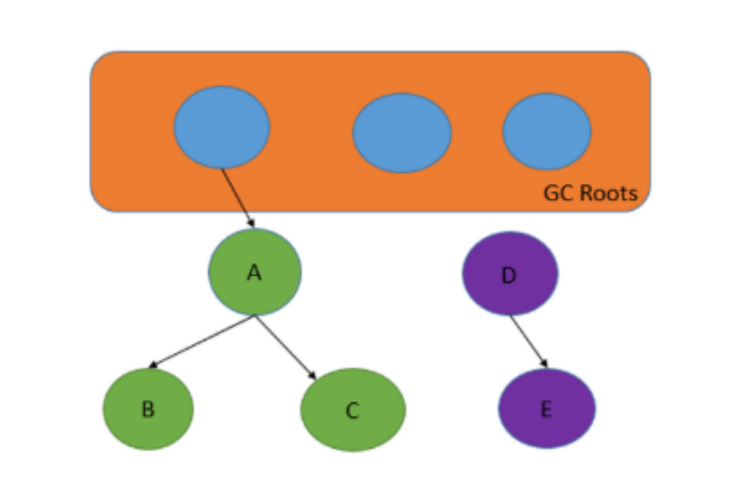
- 对象 A、B、C 可以被遍历到,不是垃圾
- 对象 D、E 不会被遍历到,会被回收
- 目前主流虚拟机采用这种算法,包括 Orace JDK、Huawei JDK 等
垃圾回收算法
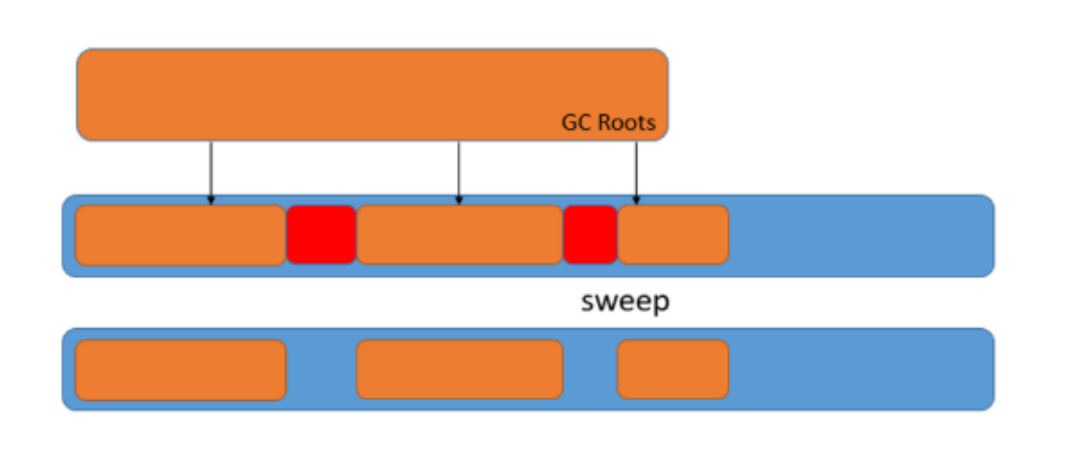
– 清除(sweep) 原理:
- 将垃圾对象所占据的内存标记为空闲内存,然后存在一个空闲列表(free list)中。当需要创建对象时,从空闲列表中寻找空闲内存,分配给新创建的对象。
优缺点:
- 优点:速度快
- 缺点:容易造成内存碎片,分配效率低
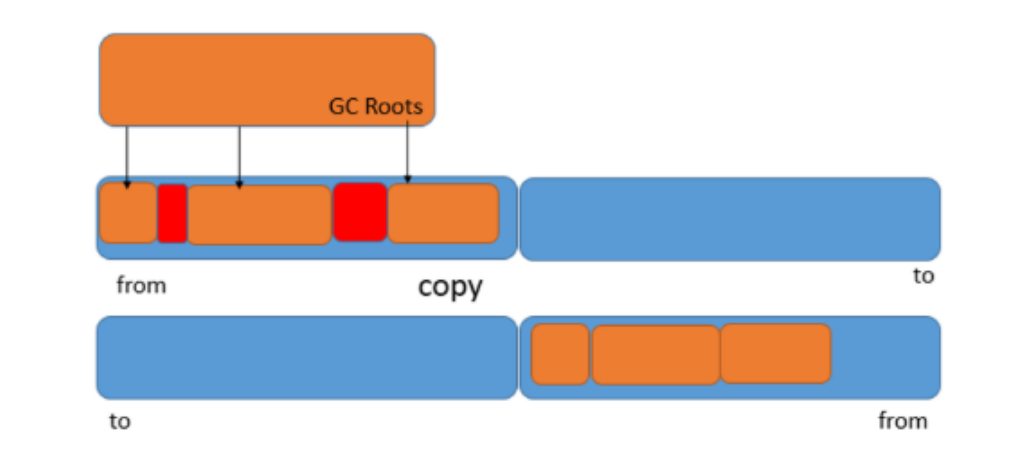
– 复制(copy)
原理:
- 将内存分为两个部分,并分别用 from 和 to 指针来维护。每次只在 from 指向的内存中分配内存,当发生垃圾回收时,将 from 指向区域中存活的对象复制到 to 指向的内存区域,然后将 from 指针和 to 指针互换位置。
优缺点:
- 优点:同压缩算法,没有内存碎片。分配速度快,局部性好
- 缺点:可用内存变少,堆空间使用效率低
垃圾收集器
– jvm 堆划分
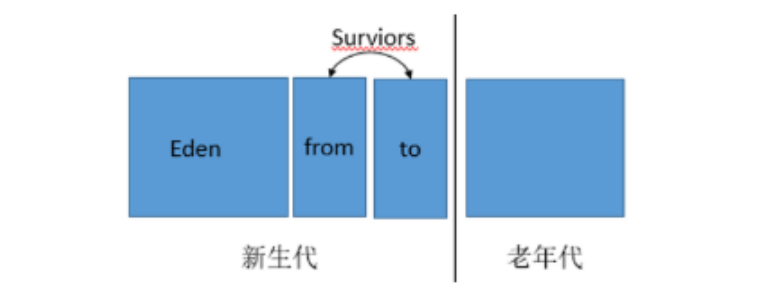 - jvm 将堆划分为新生代和老年代。新生代存放新创建的对象,当对象生存超过一定时间时,会被移动至老年代。新生代采用的 GC 称为 minor GC,老年代发生的 GC 称为 full GC 或 major GC,发生 full GC 会伴随至少一次 minor GC。
- jvm 将堆划分为新生代和老年代。新生代存放新创建的对象,当对象生存超过一定时间时,会被移动至老年代。新生代采用的 GC 称为 minor GC,老年代发生的 GC 称为 full GC 或 major GC,发生 full GC 会伴随至少一次 minor GC。
– Minor GC - 特点:发生次数多,采用时间短,回收掉大量对象 - 收集器:Serial, Parallel Scavenge, Parallel New 均采用复制算法。Serial 是单线程;Parallel New 可以看成 Serial 多线程版本;Parallel Scanvenge 和 Parallel New 类似,但更注重吞吐率,且不能与 CMS 一起使用。 – Full GC - 特点:发生次数少,耗时长 - 收集器:Serial Old(整理), Parallel Old(整理), CMS(清除)。Serial Old 是单线程的;Parallel Old 可以看成 Serial Old 的多线程版本;CMS 是并发收集器,除了初始标记和重新标记操作需要 Stop the world,其它时间可以与应用程序一起并发执行。
垃圾回收触发条件
- Minor GC
- Eden 区空间不足
- Full GC
- 老年代空间不足
- 方法区 (Metaspace) 空间不足
- 通过 minor GC 进入老年代的平均大小大于老年代的可用内存
- 老年代被写满
- 调用
System.GC,系统建议执行 full GC,但不一定执行。 ※ 禁止使用主动 GC(除非在密码、RMI 等方面),尤其是在频繁/周期性的逻辑中。
类加载
类加载过程
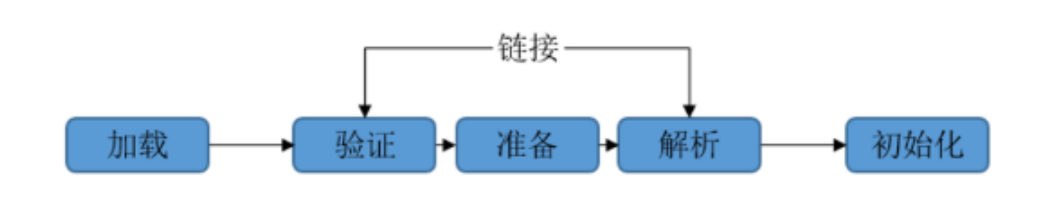
- 加载
- 将java字节码从不同数据源读到jvm中,数据源包括zip压缩包,网络,运行时计算生成,其他文件生成,数据库等。
- 链接
- 验证:验证字节码信息是否符合jvm规范。
- 准备:分配内存,并为静态变量赋初始值。
- 解析:将常量池中的符号引用转换为直接引用。也可以在初始化之后再开始,来支持java的运行时绑定。
- 初始化
- 执行静态初始化块(
static{})和类变量赋值。先初始化父类,后初始化子类。 - 不要在static块中抛出异常,否则会导致类初始化失败,抛
ExceptionInInitializerError异常,进而导致其他异常。
- 执行静态初始化块(
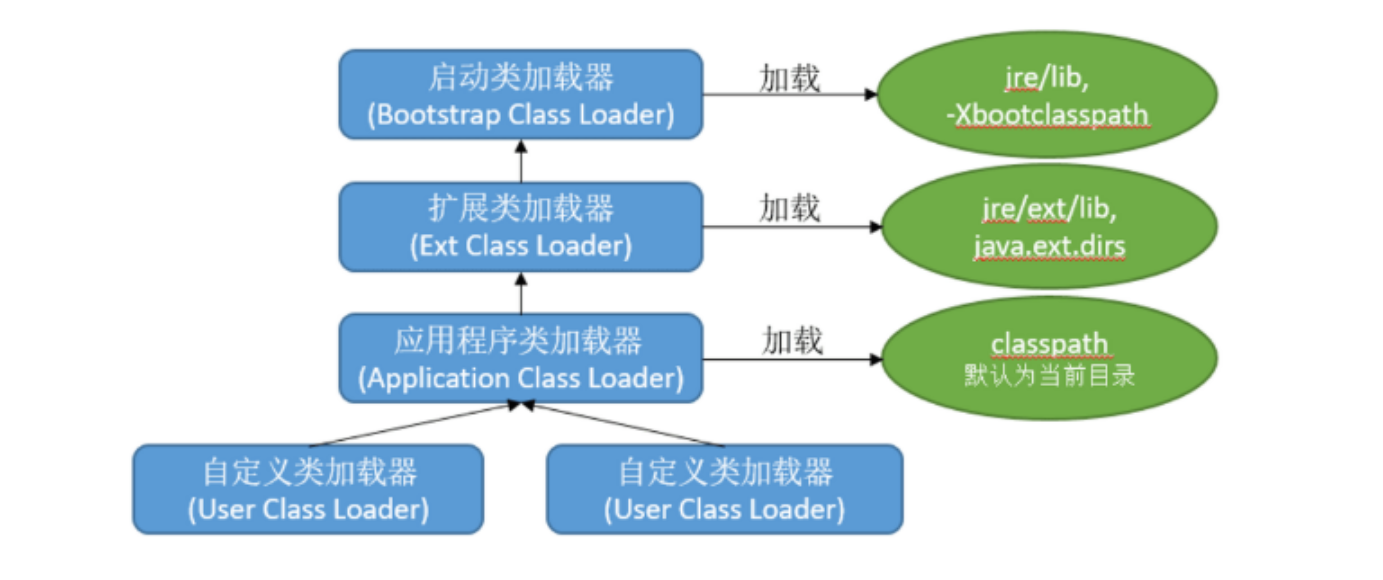
ClassLoader层次结构
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
- 双亲委派(其实叫单亲委派更合适):先由父类加载器加载,加载不到后再由子类加载器加载。
- 如果Class文件不在父类的加载路径中,则由子类加载,如果仍然找不到,抛
ClassNotFoundException异常。 - 先加载JDK中的类,再加载用户的类。
类初始化过程
- 时机
- JVM启动时,先初始化用户指定的主类
- 初始化子类之前,先初始化父类
- 访问类的静态变量或静态方法
- 创建类实例
- 反射调用类
- 特点
- JVM会加锁来保证类初始化只进行一次,可以用来实现单例模式
class Singleton {
private Singleton() {}
private static class LazyHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
对象初始化顺序
- 代码执行顺序
- 父类静态代码块
- 子类静态代码块
- 父类代码块
- 父类构造函数
- 子类代码块
- 子类构造函数
public class Test {
public static void main(String[] args) {
new B();
}
}
class A {
static {
System.out.println("A static code");
}
{
System.out.println("A code");
}
public A() {
System.out.println("A constructor code");
}
}
class B extends A {
static {
System.out.println("B static code");
}
{
System.out.println("B code");
}
public B() {
System.out.println("B constructor code");
}
}
// A static code
// B static code
// A code
// A constructor code
// B code
// B constructor code
Java编译与优化
Javac编译器

- 过程
- 源文件 > 字节码
- 语义分析
- 符号表填充:符号地址和符号信息构成
- 处理注解:编译期注解
- 属性分析:类型检查、常量折叠等
- 数据流分析:局部变量赋值,方法每条路径是否有返回值,受检异常等
- 去除语法糖:泛型、变长参数、装箱和拆箱
- 生成字节码
- 选项
-g:生成所有调试信息,包括行号,局部变量,源文件。默认只有行号和源文件。-source <release>:指定可以接受的源文件的版本为release-target <release>:指定生成class文件的版本为release-Xlint:all:打开所有的编译告警
Java 即时编译器
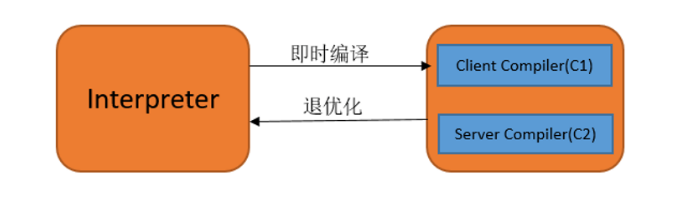
- 过程
- 字节码 > 机器码
- JVM执行状态
- 解释执行
- 没有Profiling的C1执行
- 有方法调用和回边执行次数Profiling的C1执行
- 有完整Profiling的C1执行
- C2执行
- 效率
- 对于C1,过程2稍高于过程3,过程3比过程4高出30%
- C2代码的执行效率比C1高出30%,几乎能达到GNU C++编译器使用-O2的优化程度
- 只打开C1:
-XX:TieredStopAtLevel=1 - 只打开C2:
-XX:-TieredCompilation
- 即时编译器(Just In Time, JIT)触发条件
- 方法被执行多次
- 方法中的循环体被执行多次
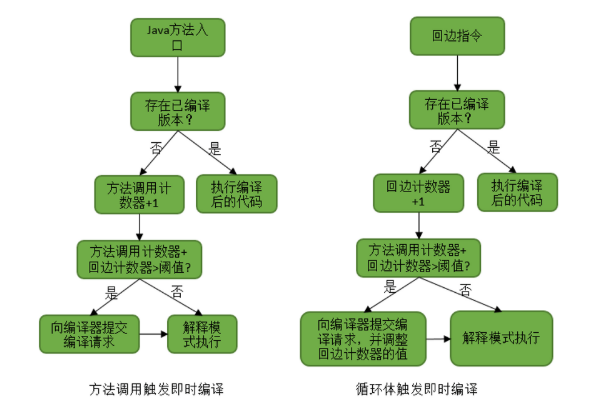
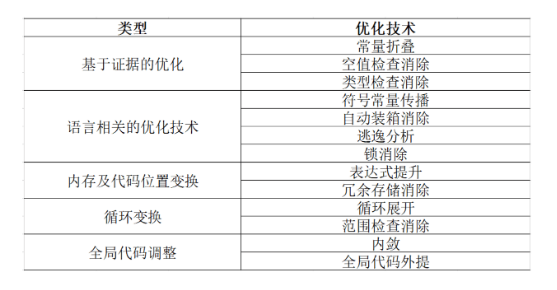
- 优化
- 实验
-XX:+PrintCompilation查看被编译的方法-XX:+PrintInlining查看被内联的方法
- 内联条件
-XX:CompileCommand:inline指令指定的方法。- 方法调用次数越多,方法越小,越容易被内联。
-XX:CompileCommand:dontinline或exclude指定的方法,不会被内联。
JDBC数据库开发
JDBC是Java程序访问数据库的标准接口,不依赖于特定的数据库。
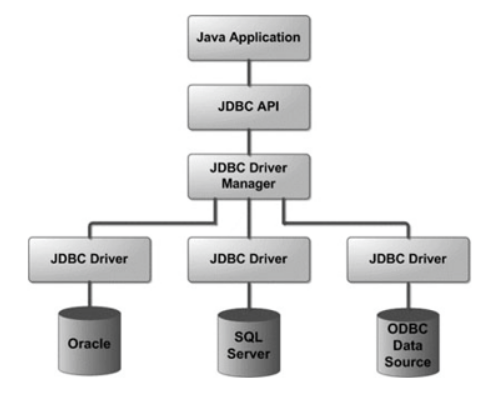
基本组件
DriverManager负责管理驱动程序,使用已注册的驱动程序进行连接DataSourceDriverManager的getConnection()方法直接建立了与数据库的连接,资源开销较大- 连接池:
DataSource通过一层简单的封装,将DriverManager建立的Connection通过Pool管理起来 - 替代
DriverManager,以JNDI(Java Naming Directory Interface)的形式对外提供 - DataSource有三种类型的实现:
- 基本实现——生成标准
Connection,与DriverManager相同 - 对象连接池实现——生成自动参与连接池的
Connection对象,此实现与中间层连接池管理器一起使用 - 分布式事务实现——生成一个
Connection对象,该对象可用于分布式事务,并且几乎始终参与连接池;此实现与中间层事务管理器一起使用,并且几乎始终与连接池管理器一起使用
- 基本实现——生成标准
DataSource对象的属性在需要时可以修改。例如,如果将数据源移动到另一个服务器,则可更改与服务器相关的属性。其优点是,因为可以更改数据源的属性,所以任何访问该数据源的代码都无需更改。
Statement- 提供了执行语句和获取结果的基本方法
- 每次执行都需要编译SQL
- 无法防止SQL注入
PreparedStatement- 预编译,缓存的预编译命令可以提高性能
- 简单有效防止参数的SQL注入
- 代码示例:
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.sql.*;
import java.util.Properties;
public class Test {
public static void main(String[] args) throws IOException, SQLException {
executeQuery(10, "yuechen");
}
private static void executeQuery(int id, String name) throws SQLException {
String sql = "select & from people p where p.id = ? and p.name = ?";
Connection conn = null;
PreparedStatement stat = null;
ResultSet rs = null;
try {
conn = getConnection();
stat = conn.prepareStatement(sql);
stat.setInt(1, id);
stat.setString(2, name);
rs = stat.executeQuery();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (rs != null) {
rs.close();
}
if (stat != null) {
stat.close();
}
if (conn != null) {
conn.close();
}
}
}
public static Connection getConnection() throws IOException, SQLException {
var props = new Properties();
try (InputStream in = Files.newInputStream(Paths.get("database.properties"))) {
props.load(in);
}
var drivers = props.getProperty("jdbc.drivers");
if (drivers != null) {
System.setProperty("jdbc.drivers", drivers);
}
var url = props.getProperty("jdbc.url");
var username = props.getProperty("jdbc.username");
var password = props.getProperty("jdbc.password");
return DriverManager.getConnection(url, username, password);
}
}
CallableStatement只用于存储过程
3个执行SQL语句的方法
execute():可执行任何SQL语句,可能会产生多个ResultSet和更新计数,较少使用- 返回true:执行后第一个结果为
ResultSet
- 返回true:执行后第一个结果为
executeQuery():产生单个ResultSetexecuteUpdate():用于执行DML语句(insert, update, delete)和DDL语句(create table, drop table)
truncate, delete, drop
- truncate和drop是DDL语言,执行后自动提交,delete可以回滚
- truncate和delete只删除数据,不删除表结构
ResultSet的 fetchSize
- 一次数据库交互读取的记录数,fetchSize越大客户端内存消耗越大,性能越快
- 配置过大有OOM风险
JDBC 资源关闭
- 由于垃圾回收的线程级别是最低的,为了充分利用数据库资源,有必要显式关闭它们,尤其是使用Connection Pool的时候;
- 最优经验是按照
ResultSet,Statement,Connection的顺序执行close(); - 为了避免由于java代码问题导致内存泄露,需要在
rs.close()和stmt.close()后面一定要加上rs = null和stmt = null; - 如果一定要传递
ResultSet,应该使用RowSet,RowSet可以不依赖于Connection和Statement。Java传递的是引用,所以如果传递ResultSet,你会不知道Statement和Connection何时关闭,不知道ResultSet何时有效。
SQL注入
防止SQL注入的方式主要有以下三类:
- 使用参数化查询:最有效的防护手段,对于sql语句中的表名、字段名、部分场景下的in条件不适用;
- 对不可信数据进行白名单校验:适用于拼接sql语句中的表名、字段名;
- 对不可信数据进行转码:适用于拼接到sql语句中的由引号限制的字段。
Socket网络编程
什么是Socket?
- 用于描述IP地址和端口,是基于网络层之上的通信方式
- 主要有TCP和UDP两种协议,Java中的Socket特指TCP连接的抽象

Socket API
- 由客户端和服务端两部分组成,其中服务端使用ServerSocket用来监听端口,接收连接请求
- 每个连接建立成功后,客户端和服务端都会产生一个Socket实例
最常用的3个API
accept()服务端接收连接请求,产生一个Socket实例getInputStream()获取Socket的输入流,用于读取数据getOutputStream()获取Socket的输出流,用于写入数据
开发注意要点
- 每次建立连接都会产生新的Socket实例,在连接使用完成或产生异常时需要主动调用
close()方法关闭资源 - 客户端Socket的连接
connect()和关闭close()都是阻塞方法,需要传入地址和端口的构造方法在内部调用connect()因此也是阻塞的 - 早期Java对于IO资源的关闭是繁琐的,建议使用
try-with-resources语句自动处理close()调用 - 从Socket中获取的输入输出流,可通过Socket对象统一关闭,不需要独立处理
- 服务端的
accept()方法是阻塞的,若要接收多个客户端的连接请求,需要借助多线程处理 - 从Socket中获取的输入输出流都是BIO,因此所有的读写调用都是同步阻塞IO
- 服务端处理每个连接都需要占用一个线程资源,实际性能较差,因此直接使用Socket的网络编程作为基础学习即可,实际生产很少使用
服务端代码示例
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class Server {
public static void main(String[] args) throws IOException {
try (var server = new ServerSocket(8080)) {
try (Socket incoming = server.accept()) {
InputStream is = incoming.getInputStream();
OutputStream os = incoming.getOutputStream();
try (var in = new Scanner(is, StandardCharsets.UTF_8)) {
var out = new PrintWriter(new OutputStreamWriter(os, StandardCharsets.UTF_8), true);
out.println("Hi");
var done = false;
while (!done && in.hasNextLine()) {
var line = in.nextLine();
out.println("Echo: " + line);
if (line.trim().equals("Stop")) {
done = true;
}
}
}
}
}
}
}
客户端代码示例
import java.io.IOException;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class Client {
public static void main(String[] args) throws IOException {
try (var socket = new Socket("localhost", 8080);
var in = new Scanner(socket.getInputStream(), StandardCharsets.UTF_8)) {
handleInput(socket.getOutputStream());
while (in.hasNextLine()) {
var line = in.nextLine();
System.out.println(line);
}
}
}
private static void handleInput(OutputStream os) {
Runnable runnable = () -> {
try (var line = new Scanner(System.in, StandardCharsets.UTF_8)) {
var out = new PrintWriter(new OutputStreamWriter(os, StandardCharsets.UTF_8), true);
while (line.hasNextLine()) {
out.println(line.nextLine());
}
} catch (Exception e) {
e.printStackTrace();
}
};
new Thread(runnable).start();
}
}